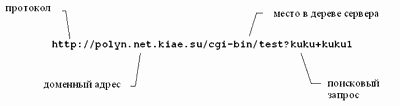
3.5.5. Протокол обмена гипертекстовой информацией (HyperText Transfer Protocol, HTTP 1.0.)
HTTP - это протокол прикладного уровня, разработанный для обмена гипертекстовой информацией в сети Internet. Протокол используется одной из популярнейших систем Сети - Word Wide Web - с 1990 года.
Реальная информационная система требует гораздо большего количества функций, чем просто поиск. HTTP позволяет реализовать в рамках обмена данными набор методов доступа, базирующихся на спецификации универсального идентификатора ресурсов (Universal Resource Identifier), применяемого в форме универсального локатора ресурсов (Universe Resource Locator) или универсального имени ресурса (Universal Resource Name). Сообщения по сети при использовании протокола HTTP передаются в формате, схожим с форматом почтового сообщения Internet (RFC-822) или с форматом сообщений MIME (Multiperposal Internet Mail Exchange). HTTP используется для взаимодействия программ-клиентов с программами-шлюзами, разрешающими доступ к ресурсам электронной почты Internet (SMTP), спискам новостей (NNTP), файловым архивам (FTP), системам Gopher и WAIS. Протокол разработан для доступа к этим ресурсам посредством промежуточных программ-серверов (proxy), которые позволяют передавать информацию между различными информационными службами без потерь. Протокол реализует принцип "запрос/ответ". Запрашивающая программа - клиент - инициирует взаимодействие с отвечающей программой - сервером, и посылает запрос, включающий в себя метод доступа, адрес URI, версию протокола, похожее по форме на MIME сообщение с модификаторами типа передаваемой информации, информацию клиента, и, возможно, тело сообщения клиента. Сервер отвечает строкой состояния, включающей версию протокола и код возврата, за которой следует сообщение в форме, похожей на MIME. Данное сообщение содержит информацию сервера, метаинформацию и тело сообщения. Понятно, что в принципе, одна и та же программа может выступать и в роли сервера и в роли клиента (так собственно и происходит при использовании proxy-серверов).
При работе в Internet для обслуживания HTTP-запросов используется 80 порт TCP/IP. Практика использования протокола такова, что клиент устанавливает соединение и ждет ответа сервера. После отправки ответа сервер инициирует разрыв соединения. Таким образом, при передаче сложных гипертекстовых страниц соединение может устанавливаться несколько раз. Остановимся более подробно на механизме взаимодействия и форме передаваемой информации.
3.5.5.1. Форма запроса клиента
Программа-клиент посылает после установления соединения запрос серверу. Этот запрос может быть в двух формах: в форме полного запроса и в форме простого запроса. Простой запрос содержит метод доступа и запрос ресурса. Например:
GET http://polyn.net.kiae.su/
В этой записи слово GET обозначает метод доступа GET, а http://polyn.net.kiae.su/ - это запрос ресурса. Клиенты, которые способны поддерживать версии протокола выше 0.9 должны пользоваться полной формой запроса. При использовании полной формы в запросе указываются строка запроса, несколько заголовков (заголовок запроса или общий заголовок) и, возможно, тело обозначения ресурса. В форме Бекуса-Наура общий вид полного запроса выглядит так:
<Полный запрос> := <Строка Запроса> (<Общий заголовок>|<Заголовок
запроса>|<Заголовок обозначения ресурса>)<символ
новой строки>[<тело ресурса>]
Квадратные скобки здесь обозначают необязательные элементы заголовка. Строка запроса - это, практически, простой запрос ресурса. Отличие состоит в том, что в строке запроса можно указывать различные методы доступа и за запросом ресурса следует указывать версию протокола. Например, для вызова внешней программы можно использовать следующую строку запроса:
POST http://polyn.net.kiae.su/cgi-bin/test HTTP/1.0
В данном случае используется метод POST и протокол версии 1.0.
3.5.5.2. Методы доступа
В настоящее время в практике World Wide Web реально используются только три метода доступа: POST, GET, HEAD.
GET - метод, позволяющий получить данные, заданные в форме URI в запросе ресурса. Если ссылаются на программу, то возвращается результат выполнения этой программы, но не текст программы. Дополнительные данные, которые надо передать для обработки, кодируются в запрос ресурса. Имеется разновидность метода GET - условный GET. При использовании этого метода сервер ответит на запрос только в том случае, если будут выполнены условия передачи. Это позволяет разгрузить сеть, избавив ее от передачи ненужной информации. Условие указывается в поле "if-Modified-Since" заголовка запроса. При использовании метода GET в поле тела ресурса возвращается собственно затребованная информация (текст HTML-документа, например).
HEAD - метод, аналогичный GET, но не возвращает тела ресурса. Используется для получения информации о ресурсе. Условного HEAD не существует. Данный метод используется для тестирования гипертекстовых ссылок.
POST - этот метод разработан для передачи большого объема информации на сервер. Им пользуются для аннотирования существующих ресурсов, посылки почтовых сообщений, работы с формами интерфейсов к внешним базам данных и внешним исполняемым программам. В отличии от GET и HEAD, в POST передается тело ресурса, которое и является информацией из поля форм или других источников ввода. В первых версиях протокола были определены и другие методы доступа (DELETE, например), но они не нашли должного применения. Многие функции, которые возлагали на эти методы, можно успешно выполнять через POST.
Изменение числа методов доступа отражает практику использования HTTP. Однако, с исторической и методической точек зрения, первые версии протокола представляют несомненный интерес, особенно раздел, описывающий методы доступа. В версии 1993 года насчитывалось 13 различных методов доступа. Среди этих методов были такие, например, как:
Из этого списка видно, что протокол был действительно максимально ориентирован на работу с гипертекстовыми распределенными системами, причем не только с точки зрения потребителя, но и с точки зрения разработчика подобных систем. Однако, во-первых, как показывал опыт, практически не использовались методы доступа, связанные с изменением информации. Это объясняется прежде всего соображениями безопасности. Ни один администратор не позволит неизвестно кому менять информацию на его сервере. Во-вторых, методы SPACEJUMP и SEARCH были с успехом заменены на функционально аналогичные CGI-скрипты. Из этого не следует, что их возрождение невозможно, например, в язык гипертекстовой разметки вернулись ссылки, общие для всего документа, но пока их реализация в протоколе отложена. В-третьих, не нашли практической реализации методы установления/удаления ссылок LINK и UNLINK. Но необходимость в них растет и связана она с реорганизацией сети. Многие информационные ресурсы меняют свои адреса, что вносит беспорядок в структуру сети, где и без этого начинающему пользователю трудно что-либо найти. Одним словом, вопрос о новых методах доступа все еще открыт, поэтому, видимо, спецификация HTTP еще не вышла на стадию RFC и остается в виде Internet Draft.
В обеих формах запроса важное место занимает форма запроса ресурса, которая кодируется в соответствии со спецификацией URI. Применительно к World Wide Web эта спецификация получила название URL. При обращении к серверу можно использовать как полную форму URL, так и упрощенную.
Полная форма содержит тип протокола доступа, адрес сервера ресурса, и адрес ресурса на сервере (рисунок 3.27).
Рис. 3.27. Полный адрес ресурса
Однако такой адрес реально нужен для работы через промежуточный сервер, так как тот может пересылать запросы. При обращении к первичному серверу клиент может опускать протокол и адрес, устанавливая взаимодействие с сервером по адресу, указанному в URL (в исходном документе), и порту 80, передавая только путь от корня сервера.
Здесь пока оставим обсуждение элементов запроса и обратимся к структуре ответа сервера. Дело в том, что элементы заголовков запроса и ответа одинаковые, и поэтому их имеет смысл обсудить после определения структуры ответа сервера.
3.5.5.3. Ответ сервера
Ответ сервера может быть, как и запрос, упрощенным или полным. При упрощенном ответе сервер возвращает только тело ресурса (например, текст HTML-документа). При полном ответе клиенту возвращается строка состояния (Status-Line), общий заголовок, заголовок ответа, заголовок ресурса и тело ресурса. В форме Бекуса-Наура полный ответ представляется следующим образом:
<Полный ответ> := <Строка состояния> (<Общий заголовок>|<Заголовок
ответа>|<Заголовок ресурса>) <символ новой
строки>[<тело ресурса>]
Строка состояния состоит из версии протокола, кода возврата и краткого описания этого кода. Например, она может выглядеть так:
"HTTP/1.0 200 Success".
Заголовок ответа сервера может состоять из адреса URI запрашиваемого ресурса, и/или наименования программы сервера, и/или кода идентификации для работы в защищенном режиме. Состав полей заголовка ресурса является общим и для запроса клиента и для ответа сервера, и состоит из разрешения на метод доступа, типа кодировки тела ресурса (содержания ресурса), длины тела ресурса, типа ресурса, время действия данной копии ресурса, времени последнего изменения ресурса и расширения заголовка.
Рассмотрим более подробно поля заголовка, обращая внимание на реальное применение каждого из них и возможность проявления ошибок при обработке этих полей разными программами (серверами и клиентами).
Если в заголовке ответа сервера указано предложение Location, то это значит, что требуемый ресурс находится по другому адресу и его надо запросить заново. Такая процедура называется перенаправлением. Перенаправление в заголовке будет выглядеть как:
Location: http://apollo.polyn.kiae.su/risk/riskform.html
Имя и версия сервера указываются в поле Server. При использовании сервера Церн данное поле будет выглядеть как:
Server: CERN/3.0 libwww/2.17
В заголовке может встречаться и поле контроля доступа WWW-Authenticate, которое определяет способ доступа к закрытым ресурсам. Например, это поле может выглядеть как:
WWW-Athenticate: Basic realm="WallyWorld"
Кроме рассмотренных выше полей, в заголовке могут встретиться и другие поля, которые определяют содержание тела передаваемого ресурса. Эти поля относятся к заголовку ресурса, но в ответе сервера они встречаются вперемешку с общими полями. Поле Allow определяет разрешенные методы доступа к ресурсу:
Allow: GET,HEAD
Поле Сontent-Encoding определяет тип кодирования передаваемого ресурса:
Content-Encoding: x-gzip
В данном случае указывается, что ресурс является заархивированным файлом в формате zip. Обычно ресурсы хранятся в виде, указанном в данном поле, и при их получении клиент должен обеспечить их преобразование в приемлемый для отображения вид. Это своего рода предобработка данных, которая базируется обычно на MIME типах. В машинах, где недостаточно памяти на видео-адаптерах, используют предобработку для преобразования изображений в приемлемый для отображения вид. Так, например, для персональных компьютеров с 512 КБ памяти на видеоадаптере используют предобработку для преобразования 256-цветных картинок в 16-цветные. Если этого не делать, то можно наблюдать интересный эффект: в Unix-системах при работе с программами Chimera и Mosaic 256-цветные картинки удваиваются, т.е. вместо одной на экране отображаются последовательно две картинки. Это связано с тем, что для 256 цветов нужно ровно в два раза больше памяти, чем для 16. Для того, чтобы избежать двойного отображения встроенных в текст картинок, их следует преобразовать.
Другим полем, которое проявляет себя при работе в сети, порождая ошибки отображения ранними версиями программ просмотра или ранним версиями программ серверов, является поле Content-Length. Поле Content-Length указывает размер (количество байтов) передаваемого ресурса. Это поле указывается как клиентом при работе по методу POST, так и сервером при ответе на запросы клиентов. При этом в ранних версиях программ-серверов может порождаться ошибка, вызванная возможностью вставки сервером некоторой информации в текст ресурса. Например, сервер NCSA (1.3) позволяет вставлять в текст HTML-документов фрагменты текста из других файлов при помощи выражения типа:
<!--#includes virtual="/include/commonheader.html" -->
В данном случае речь идет об общей заставке для всех документов некоторого раздела. На сервере в директории документов хранится файл одного размера, но после выполнения подстановки размер файла увеличивается, однако, сервер сообщает клиенту старый размер файла. Новые программы-клиенты (Netscape, Mosaic) неправильно обрабатывают такой ответ и информация не отображается.
Поле Content-Type определяет тип информации, передаваемой сервером. Наиболее часто используются типы text/play - простой тест и text/html - документ в формате HTML. Для сокращения трафика по сети существует несколько полей, связанных со временем передачи информации и периодичностью ее изменения на серверах. Поле Date определяет время отправки сообщения. Информация из данного поля сохраняется в файле статистики сервера и может быть использована для анализа доступа к ресурсам сервера из сети.
Поле Expires определяет время годности ресурса для использования. Если время использования вышло, то ресурс не должен передаваться. Точнее, его не следует передавать и принимать. О поле if-Modified-Sience уже упоминалось. Оно предназначено для того, чтобы не передавать имеющиеся у клиента копии ресурса, если не были произведены его изменения. Поле Pragma используется при передаче сообщений с сервера на сервер. Реально известно только одно значение данного поля: no-cache, которое запрещает запоминать в буфере данные для последующего использования.
Поле Referer используется для того, чтобы указать, из какого ресурса была осуществлена ссылка на ресурс. Данное поле - это мечта любого администратора базы данных сети. При помощи информации из этого поля можно определить, в каких WWW-страницах прописан конкретный сервер. От этого зависит количество обращений к серверу, "качество" пользователей, время отклика на информацию, размещаемую на сервере. При необходимости можно связаться с администратором этого сервера и уведомить его об изменениях на вашем сервере.
3.5.5.4. Защита сервера от несанкционированного доступа
Отдельное место при обсуждении протокола занимают вопросы, связанные с обеспечением защиты ресурсов сервера от несанкционированного доступа. Как было отмечено в предыдущих разделах, первоначально разработка защищенных способов обмена данными в системе World Wide Web не предполагалась. Однако быстрое развитие популярности системы привело к тому, что многие коммерческие организации стали устанавливать серверы HTTP на свои машины. Кроме этого, конфиденциальной информации много и в научно-исследовательских государственных организациях. Таким образом, возникла необходимость в разработке механизмов защиты информации для системы WWW.
Проблема защиты информации на Internet - это отдельная большая тема. В данном разделе мы рассмотрим только обеспечение безопасности при использовании серверов HTTP.
При обсуждении этой проблемы полезно вспомнить схему WWW-технологии (рисунок 3.26). Из этой схемы видно, что в этой технологии имеется как минимум две потенциальные "дыры" .
Первая связана с чтением защищенных текстовых файлов. Для решения этой задачи имеется достаточно много традиционных механизмов, встроенных в операционные системы. Проблема возникает, если администратор системы решит использовать для размещения WWW-файлов и FTP-архива одно и тоже дисковое пространство. В этом случае защищенные WWW-файлы окажутся доступными для "анонимного" FTP-доступа. Многие серверы разрешают создавать в дереве поддерживаемых ими документов "домашние" страницы пользователей с помощью методов POST и GET. Это значит, что пользователи могут изменять информацию на компьютере сервера. Данные, вводимые пользователем, передаются как тело ресурса при методе POST через стандартный ввод, а методе GET через переменные окружения. Естественно, что разрешение создания файлов на сервере протокола HTTP создает потенциальную опасность доступа к защищенной информации лиц, не имеющих права доступа к ней. Решается эта проблема путем создания специальных файлов прав пользователей сервера WWW.
Рис. 3.28. Схема управления ресурсов сервером HTTP
Вторая возможность проникновения в компьютерную систему через сервер WWW связана с CGI-скриптами. CGI-скрипт - это программа, которую сервер HTTP может запускать для реализации механизмов, не предусмотренных в протоколе. Многие достаточно мощные информационные механизмы WWW реализованы посредством CGI-скриптов. К ним относятся: программы поиска по ключевым словам, программы реализации графических гипертекстовых ссылок - imagemap, программы сопряжения с системами управления базами данных и т.п. Естественно, что при этом появляется возможность получить доступ к системным ресурсам. Обычно внешняя программа запускается с идентификатором пользователя, отличным от идентификатора сервера. Данный идентификатор указывается при конфигурировании сервера. Наиболее безопасным здесь является идентификатор пользователя nobody (65534). Основная опасность скриптов заключена в том, что данные в скрипт посылаются программой-клиентом. Для того, чтобы в качестве параметров не передавали "подозрительных" данных, многие серверы производят проверку параметров на наличие допустимых символов. Особенно опасны скрипты для тех, кто использует сервер на персональном компьютере с MS-Windows 3.1. В этом случае файловая система практически не защищена. Одной из характерных для скриптов проблем является размер входных данных. Многие "умные" серверы обрезают слишком большие входные потоки и тем самым защищают скрипты от "поломки". Кроме перечисленных выше опасностей, порождаемых природой сети и системы WWW, существует еще одна, связанная с такой экзотикой, как мобильные коды. Мобильный код - это программа, которая может передаваться по сети для выполнения ее клиентом. Код встраивается в WWW-страницу при помощи тага <APP ...> - application. Например, Sun выпустила WWW-клиента HotJava, который позволяет интерпретировать язык Java. Существуют клиенты и для других языков, Safe-Tcl для Tcl, например. Главное назначение таких средств - реализация мультимедийных страниц и реализация работы в rеal-time. Опасность применения такого сорта страниц очевидна, так как повторяет способ распространения различного сорта вирусов. Однако пока речи о защите от такого сорта "взломов" не идет, видимо в силу довольно ограниченного применения данной возможности в сети.
Практически любой сервер имеет механизм назначения паролей и прав доступа для различных пользователей, который базируется на схеме идентификации протокола HTTP 1.0. Данная схема предполагает, что программа-клиент посылает серверу идентификатор пользователя и пароль. Понятно, что такой механизм не обеспечивает защиты передаваемой по сети информации, и она может стать легкой добычей злоумышленников.
Для того, чтобы этого не происходило, в рамках WWW ведется разработка других схем защиты. Они строятся на двух широко известных принципах: контроль доступа по IP-адресам и шифрация. Первый принцип реализован в программе типа "стена" (Firewall). Сервер разрешает обращаться к себе только с определенных IP-адресов и выполнять только определенные операции. Слабое место такого подхода с точки зрения WWW заключается в том, что обратиться могут через сервер-посредник, которому разрешен доступ к ресурсам защищенного первичного сервера. Поэтому применяют шифрование паролей и идентификаторов по аналогии с системой "Керберос". На принципе шифрования построен новый протокол SHTTP, который реализован в серверах Netsite (последние версии), Apachie и в новых серверах CERN и NCSA. Однако реально широкого применения это программное обеспечение еще не нашло и находится в стадии развития, а потому содержит достаточно большое количество ошибок.
Завершая обсуждение протокола HTTP и способов его реализации, нужно отметить, что в качестве широко доступного информационного ресурса WWW уже состоялась, следующий шаг - серьезные коммерческие применения. Но для этого необходимо еще внедрить в практику защищенные протоколы обмена, базирующиеся на HTTP. В последнее время появилось много новых программ, реализующих протокол HTTP. Это серверы и клиенты, написанные как для новых компьютерных платформ, так и для возможностей SHTTP. Реальную возможность попробовать свои силы в разработке различных WWW-приложений имеют и отечественные программисты.
3.5.6. Universal Resource Identifier - универсальный идентификатор. Спецификация универсального адреса информационного ресурса в сети
Из всех спецификаций World Wide Web только спецификация URI доведена до состояния RFC. За этим стандартом закреплен номер 1630. Выпущен этот документ в 1994 году и отражает состояние информационных ресурсов Internet на это время.
URI определяет способ записи (кодирования) адресов различных информационных ресурсов при обращении к ним из страниц WWW. Однако в последнее время данная спецификация стала встречаться и в почтовых сообщениях. При этом видимо предполагается, что пользователи почты должны использовать клиентов, поддерживающих этот формат сообщения (HTML). Реально, речь может идти о клиентах MIME.
Необходимость в URI была понятна разработчикам WWW c момента зарождения системы, т.к. предполагалось объединение в единую информационную среду средств, использующих различные способы идентификации информационных ресурсов. Первоначально это были FTP-архивы, информационно-поисковая система Alise, и справочная система ЦЕРН. Однако Бернерс-Ли подошел к делу основательно и разработал спецификацию, которая включала в себя обращения к FTP, Gopher, WAIS, Usenet, E-mail, Prospero, Telnet, Whois, X.500 и, конечно, HTTP (WWW). В итоге была разработана универсальная спецификация, которая позволяет расширять список адресуемых ресурсов за счет появления новых схем.
Место применения URI - гипертекстовые ссылки, которые записываются в тагах <A HREF=URI> и <LINK HREF=URI>. Встраиваемые графические объекты также адресуются по спецификации URI в тагах <IMG SRC=URI> и <FIG SRC=URI>. Реализация URI для WWW называется URL (Uniform Resource Locator). Точнее, URL - это реализация схемы URI, отображенная на алгоритм доступа к ресурсам по сетевым протоколам. Существует еще и URN (Uniform Resource Name), которое отображает URI в пространство имен на сети. Появление URN связано с желанием адресовать части почтового сообщения MIME. Но здесь есть момент, который находится в стадии дебатов. Сообщение "живет" не более 5 дней. Если оно сохранено, то его можно превратить в другой информационный ресурс, например, WWW-страницу. Поэтому судьба URN еще не решена.
3.5.6.1. Принципы построения адреса WWW
В основу URI были заложены следующие принципы:
Расширяемость была достигнута за счет выбора определенного порядка интерпретации адресов, который базируется на понятии "адресная схема". Идентификатор схемы стоит перед остатком адреса, отделен от него двоеточием и определяет порядок интерпретации остатка.
Полнота и читаемость порождали коллизию, связанную с тем, что в некоторых схемах используется двоичная информация. Эта проблема была решена за счет формы представления такой информации. Символы, которые несут служебные функции, и двоичные данные отображаются в URI в шестнадцатеричном коде и предваряются символом "%".
Прежде, чем рассмотреть различные схемы представления адресов приведен пример простого адреса URI:
http://polyn.net.kiae.su/polyn/index.html
Перед двоеточием стоит идентификатор схемы адреса - "http". Это имя отделено двоеточием от остатка URI, который называется "путь". В данном случае путь состоит из доменного адреса машины, на которой установлен сервер HTTP и пути от корня дерева сервера к файлу "index.html".
Кроме представленной выше полной записи URI, существует упрощенная. Она предполагает, что к моменту ее использования многие параметры адреса ресурса уже определены (протокол, адрес машины в сети, некоторые элементы пути). При таких предположениях автор гипертекстовых страниц может указывать только относительный адрес ресурса, т.е. адрес относительно определенных базовых ресурсов.
3.5.6.2. Схемы адресации ресурсов Internet
В RFC-1630 рассмотрено 8 схем адресации ресурсов Internet и указаны две, синтаксис которых находится в стадии обсуждения.
Схема HTTP. Это основная схема для WWW. В схеме указывается ее идентификатор, адрес машины, TCP-порт, путь в директории сервера, поисковый критерий и метка. Приведем несколько примеров URI для схемы HTTP:
http://polyn.net.kiae.su/polyn/manifest.html
Это наиболее распространенный вид URI, применяемый в документах WWW. Вслед за именем схемы (http) следует путь, состоящий из доменного адреса машины и полного адреса HTML-документа в дереве сервера HTTP.
В качестве адреса машины допустимо использование и IP-адреса:
http://144.206.160.40/risk/risk.html
Если сервер протокола HTTP запущен на другой, отличный от 80 порт TCP, то это отражается в адресе:
http://144.206.130.137:8080/altai/index.html
При указании адреса ресурса возможна ссылка на точку внутри файла HTML. Для этого вслед за именем документа может быть указана метка внутри документа:
http://polyn.net.kiae.su/altai/volume4.html#first
Символ "#" отделяет имя документа от имени метки. Другая возможность схемы HTTP - передача параметров. Первоначально предполагалось, что в качестве параметров будут передаваться ключевые слова, но, по мере развития механизма СGI-скриптов, в качестве параметров стала передаваться и другая информация.
http://polyn.net.kiae.su/isindex.html?keyword1+keyword2
В данном примере предполагается, что документ "isindex.html" - документ с возможностью поиска по ключевым словам. При этом в зависимости от поисковой машины (программы, реализующей поиск) знак "+" будет интерпретироваться либо как "AND", либо как "OR". Вообще говоря, "+" заменяет " " (пробел) и относится к классу неотображаемых символов. Если необходимо передать такой символ в строке параметров, то следует передавать в шестнадцатеричном виде его ASCII-код.
http://polyn.net.kiae.su/isindex.html?keyword1%20keyword2
В данном случае имеется один параметр, в котором два слова разделены пробелом. Символ "%" обозначает начало ASCII-кода, который продолжается до первого символа, отличного от цифры.
При использовании HTML Forms параметры передаются как поименованные поля:
http://polyn.net.kiae.su/isindex.html?field1=value1+field2=value
Значения "field1" и "field2" - это имена полей, а "value1" и "value" - их значения. При этом приведенному выше URI может соответствовать следующая HTML-форма:
<FORM ACTION=http://polyn.net.kiae.su/cgi-bin/test> Введите значения полей:<BR> Поле "field1":<INPUT NAME="filed1" VALUE="value1"><BR> Поле "field2":<INPUT NAME="field2" VALUE="value2"><BR> <HR> </FORM>
Схема FTP. Данная схема позволяет адресовать файловые архивы FTP из программ-клиентов World Wide Web. При этом программа должна поддерживать протокол FTP. В данной схеме возможно указание не только имени схемы, адреса FTP-архива, но и идентификатора пользователя и даже его пароля. Наиболее часто данная схема используется для доступа к публичным архивам FTP:
ftp://polyn.net.kiae.su/pub/0index.txt
В данном случае записана ссылка на архив "polyn.net.kiae.su" c идентификатором "anonymous" или "ftp" (анонимный доступ). Если есть необходимость указать идентификатор пользователя и его пароль, то можно это сделать перед адресом машины:
ftp://nobody:password@polyn.net.kiae.su/users/local/pub
В данном случае эти параметры отделены от адреса машины символом "@", а друг от друга двоеточием. В некоторых системах можно указать и тип передаваемой информации, но данная возможность не стандартизирована. Стандарт рекомендует определять тип по характеру данных (текстовая информация - ASCII, двоичная - IMAGE). Следует также учитывать, что употребление идентификатора пользователя и его пароля не рекомендовано, т.к. данные передаются незашифрованными и могут быть перехвачены. Реальная защита в WWW осуществляется другими средствами и построена на других принципах.
Схема Gopher. Данная схема используется для ссылки на ресурсы распределенной информационной системы Gopher. Схема состоит из идентификатора и пути, в котором указывается адрес Gopher-сервера, тип ресурса и команда Gopher.
gopher://gopher.kiae.su:70:/7/kuku
В данном примере осуществляется доступ к gopher-серверу gopher.kiae.su через порт 70 для поиска (тип 7) слова "kuku". Следует заметить, что gopher-тип, в данном случае 7, передается не перед командой, а вслед за ней.
Схема MAILTO. Данная схема предназначена для отправки почты по стандарту RFC-822 (стандарт почтового сообщения). Общий вид схемы выглядит как:
mailto:paul@quest.polyn.kiae.su
Схема NEWS. Данная схема используется для просмотра сообщений системы Usenet. Для этой схемы используется следующая нотация:
news:comp.infosystems.gopher
В данном случае можно получить статьи из группы "comp.infosystems.gopher" в режиме уведомления. Можно получить и текст статьи, но в этом случае указывают ее идентификатор:
news:086@comp.infosystems.gopher
Заказана 86 статья из группы.
Схема NNTP. Это еще одна схема получения доступа к ресурсам Usenet. В данной схеме обращение к группе comp.infosystems.gopher для получения статьи 86 будет выглядеть так:
nntp:comp.infosystems.gopher/086
Следует обратить внимание на то, что адрес сервера Usenet не указан. Программа-клиент должна быть предварительно сконфигурирована на работу с одним из серверов Usenet. Сама служба Usenet является распределенным информационным ресурсом, и группа comp.infosystems.gopher на сервере в домене kiae.su или где-либо еще в мире содержит одни и те же сообщения.
Схема TELNET. По этой схеме осуществляется доступ к ресурсу в режиме удаленного терминала. Обычно клиент вызывает дополнительную программу для работы по протоколу telnet. При использовании этой схемы необходимо указывать идентификатор пользователя, допускается использование пароля. Реально, доступ осуществляется к публичным ресурсам, и идентификатор и пароль являются общеизвестными, например, их можно узнать в базах данных Hytelnet.
telnet://guest:password@apollo.polyn.kiae.su
Схема WAIS. WAIS - распределенная информационно-поисковая система. Она работает в двух режимах: поиска и просмотра. При поиске используется форма со знаком "?", отделяющим адресную часть от ключевых слов:
wais://wais.think.com/wais?guide
В данном случае обращаются к базе данных wais на сервере wais.think.com с запросом на поиск документов со словом guide. Сервер должен вернуть клиенту список документов. После получения этого списка можно использовать вторую форму схемы wais - запрос на просмотр документа:
wais://wais.think.com/wais/wtype/039=/kuku/kuku.txt
039 - это идентификатор документа. Следует заметить, что не все клиенты умеют работать с этой схемой, и в ряде случаев следует пользоваться другими средствами. Схема wais хороша там, где надо обслуживать постоянно действующий запрос, который неизменен на протяжении длительного времени, но при этом выдает свежие документы.
Схема FILE. WWW-технология используется как в сетевом, так и в локальном режимах. Для локального режима используют схему FILE.
file:///C|/text/html/index.htm
В данном примере приведено обращение к локальному документу на персональном компьютере с MS-DOS или MS-Windows. Следует заметить, что данная схема не может быть применена к CGI-скриптам. Очень часто, однако, пользователи пытаются применить file к скрипту, что является ошибкой. Любой скрипт может быть запущен только сервером HTTP, т.к. ему надо передавать параметры и данные. Клиент запускает только программы просмотра на основе MIME-типов из заголовка сообщений сервера или по расширению файла.
Существует еще несколько схем. Эти схемы практически не используются или находятся в стадии разработки, поэтому останавливаться на них мы не будем.
Из приведенных выше примеров видно, что спецификация адресов ресурсов URI является довольно общей и позволяет проидентифицировать практически любой ресурс Internet. При этом число ресурсов может расширяться за счет создания новых схем. Они могут быть похожими на существующие, а могут и отличаться от них. Реальный механизм интерпретации идентификатора ресурса, опирающийся на URI, называется URL и пользователи WWW имеют дело именно с ним.
Назад | Содержание | Вперед
[an error occurred while processing this directive]